Synopsis
The RISC-V is an open-source and free ISA (instruction set architecture) developed at the University of California Berkeley. It becomes increasingly popular nowadays, both in industry and academia, because it allows to use the ISA without any royalties and it perfectly fits the implementation of small and low-power hardware such as IoT devices. Ariane is a 6-stage, linux-capable, open-source processor implementing RISC-V ISA (RV64GC), developed at ETH Zurich. It is highly configurable and well-tested and successfully booting Linux. Currently, the processor is single-issue, meaning that the processor can only issue one instruction per clock cycle. That is a huge performance bottleneck since most functional units in the processor will stay idle when it does not have any instructions to proceed. In this project, I will implement super-scalar issue logic which allows Ariane to issue two (or more) instructions in the same clock cycle so that the overall performance will be greatly improved
Deliverables
| Task | Details | Status |
|---|---|---|
| Wider fetch width | Generalize the instruction realigner in Ariane to support wider fetch width, i.e., 64 bit per fetch | |
| Proper branch prediction modifications for the widend fetch interface | The instruction frontend and branch prediction will encounter problems when we fetch two instruction from the memory since it is likely that the incoming instruction data is compressed and unaligned (e.g. wrapping a natural 32 bit fetch-boundary). And we also consider to add a gshare global history predictor to increase the performance | |
| Enable multi-issue in Ariane | This is the main deliverable of this project which will allow Ariane to issue two (or more) instructions in the same clock cycle | |
| Another ALU (arithmetic logic unit) | If the processor is able to issue two instruction at the same time, it is beneficial to have more functional units to process the incoming instructions at the same time. A new ALU is considered to be added to the execution stage |
![]() Not start yet
Not start yet ![]() Developing
Developing ![]() Wait for review
Wait for review ![]() Code pushed
Code pushed
Final Report
Phase 1 (PR link)
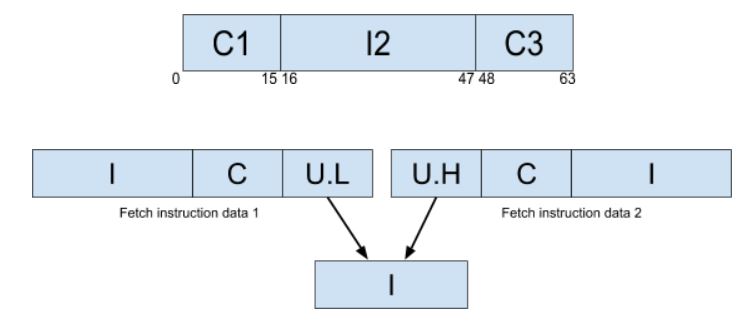
The first phase of the project involves in background knowledge learning, all the required tools setup and widening the fetch width. Tools setup was finished smoothly since the RISV tools and Ariane provides well-written documents. I used modelsim and verilator to debug my program. Before the project started, Ariane can only handle 32 bit instruction data fetch from cache. Because Ariane supports compressed 16 bit instruction, things become tricky to align the different instruction. To increase and generalize the width of fetching, instruction realigner was modified. The outputs from the aligner are addresses, valid bits and instruction data of each realigned instruction. For example, in 64 bit we can have 4 valid compressed instructions from the aligner in maximum. The basic mechanism of the realigner is to use a for-loop in System Verilog to traverse all 16 bit data trunk. Starting from the bit 0, if the next 16 data trunk is a compressed instruction, we set the valid[0] to be 0, address[0] = base_addr + 0 and data[0] = C1. Next instruction will start from bit 16. Then we check if it is a full instruction or compressed instruction. If it is a full instruction, then we set data[1] = I2 (16 to 47 bit), valid[1] = 1. Then since the previous one is a full instruction, we directly check the last 16 bit data trunk. If it is a valid compressed instruction, then we set address[2] = base_addr + 48, valid[2] = 1 and data[2] = C3 (48 to 63 bit). And in this scenario, valid[3] = 0 since we don’t have extra instructions. However, if the last 16 bit is the lower 16 bit of a full instruction, we need to save it until the next instruction data is fetched. Then we combine the 16 bits from the last fetch and lower 16 bit from this fetch into a full instruction and output it as data[0]. The entire logic gets more complex when the fetch width is wider since every 16 data trunk needs to be checked and assigned to the correct output slot based on the results from previous data trunks. This is also part of the critical path of the entire Ariane.
Phase 2 (PR link)
In the second phase of the project, we decided to add a GShare global branch predictor in Ariane to improve the performance. Details about this branch predictor can be found here. To track the global branch histories, we need to add a global branch history buffer (GHR). Whenever there is a branch resolved we need to shift in the recent branch result (taken/not taken) to GHR. When branch(s) is(are) fetched we use the branch history table (BHT) to get a branch prediction. Since there can be multiple branch instructions in the same fetch, we need to provide multiple branch predictions at the same time. If the first instruction is an unaligned instruction, we should first align it before we made the prediction for it. So in each row of BHT we have N columns where N equals to the number of maximum instructions we can fetch in each cycle (i.e., 4 if we have fetch width equals to 64). The row index is calculated by the pc address xored with global histories according to GShare definition. We also need a fetch target queue (FTQ) to record the given prediction and its index so that we can update correctly when the branch is resolved. Each entry contains the row index, a tag, a branch count and an unaligned instruction flag. If the flag is set to 1, it means that we had a branch with unaligned address and we need to realign before we update BHT. The tag is used to check whether we are using the correct entry to give the prediction. If the tag doesn’t match, we set the valid bit to 0. We used the branch counter to see when we can pop the entry because we may have more than one branch instructions in one fetch.
The tricky part in the implementation of FTQ is that we need to flush the queue properly when we encounter the overflow in FTQ, instruction queue or address queue. If the instruction is going to be replayed, then we should not push the entry to FTQ.
Phase 3 (PR link)
The third phase is about enabling the multi-issue. To implement this, we should implement the following: 1) fetch more than one from the instruction queue. 2) decode more than one instruction at the same time. 3) issue more than one instruction to execute stage.
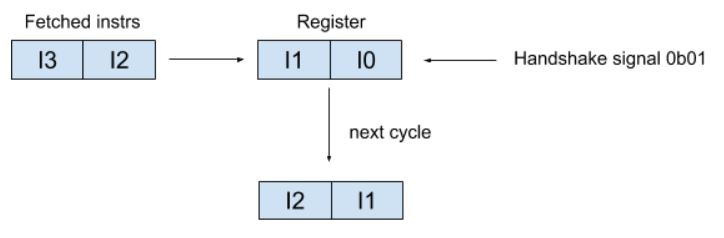
The 1) is straightforward, it counted the number of fetched instructions and increase the pointer by that amount. To enable 2), besides add more copies of decoder, we also need a register to store the decoded instructions that are stalled. The following diagram shows how we shift in the new fetched candidates. If the decoded instruction received handshake signal from issue stage, that instruction will be shifted out. Otherwise it will stay in the register.
To enable 3), we need to change the scoreboard so that it can push multiple decoded instructions to scoreboard and issue them to execute stage. To avoid the hazard, we need to check the function usages and resource dependencies among the same fetch. For example, if two instructions are two loads, we should stall the latter one because the load store unit will be used by the first load instruction. And we also stall the instruction if any source register is the destination of the previous instructions.
We also need to handle the misprediction situation. The branch instruction is resolved in the execution stage so we need to somehow “flush” the instruction after mispredicted branch. To “flush” the impact of instructions, we should 1) invalidate the input to the corresponding function unit. 2) mark the scoreboard as “flushed” so that the commit pointer can skip that entry without waiting the valid result to be 1. And there is also one corner cases when the exception happens on a mispredicted instruction. So if the instruction has a valid exception and one branch proceeds before, it should also stall.
After we are able to issue multiple instructions, it makes sense to add one more ALU and fixed length unit (FLU) that is used to writeback. In our design we have two FLU. One is used by one ALU unit and a multiplier. The other one is used by the other ALU, a CSR unit and a branch unit.